Hola colega.
Bienvenida, bienvenido al segundo número de ?R.
Comienzo con una pregunta.
¿Qué tienen en común los cuatro "problemas" que describo en el siguiente gif 👇?
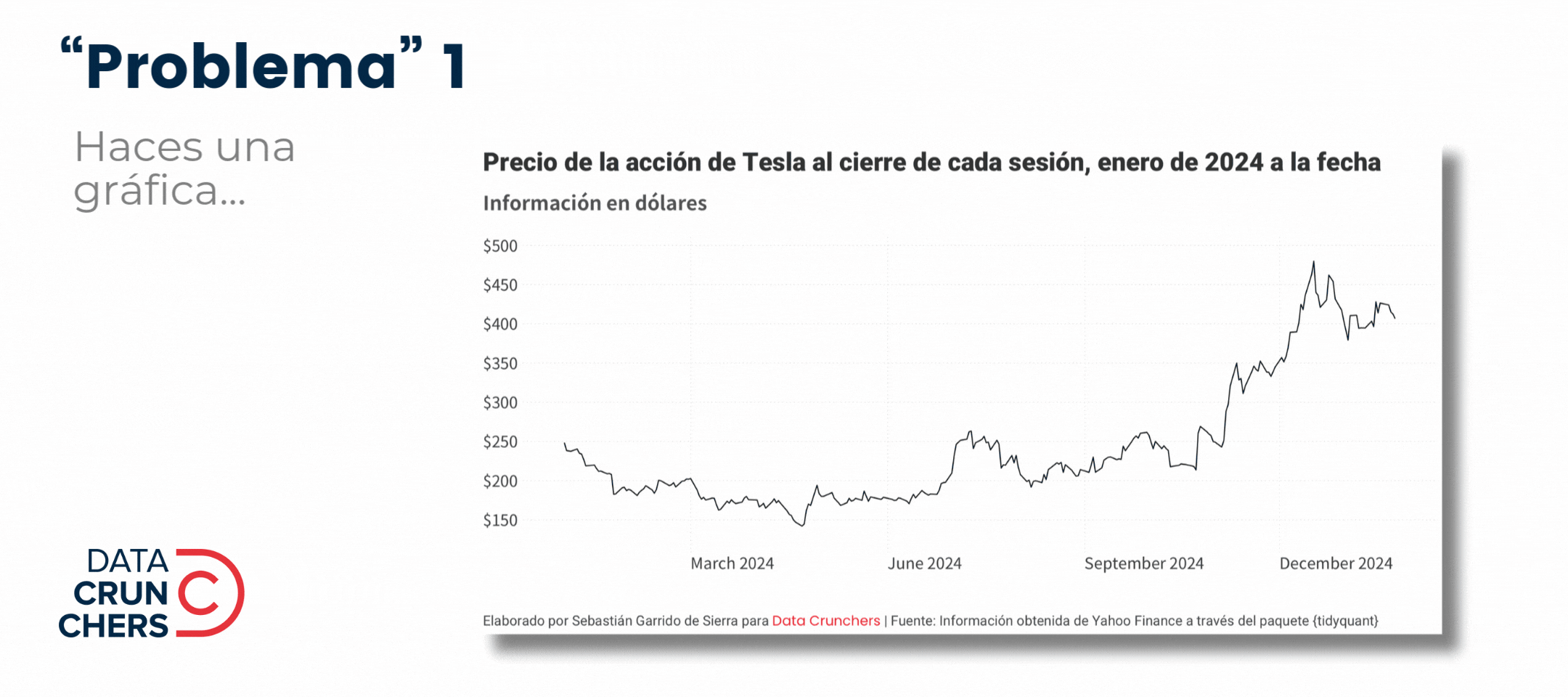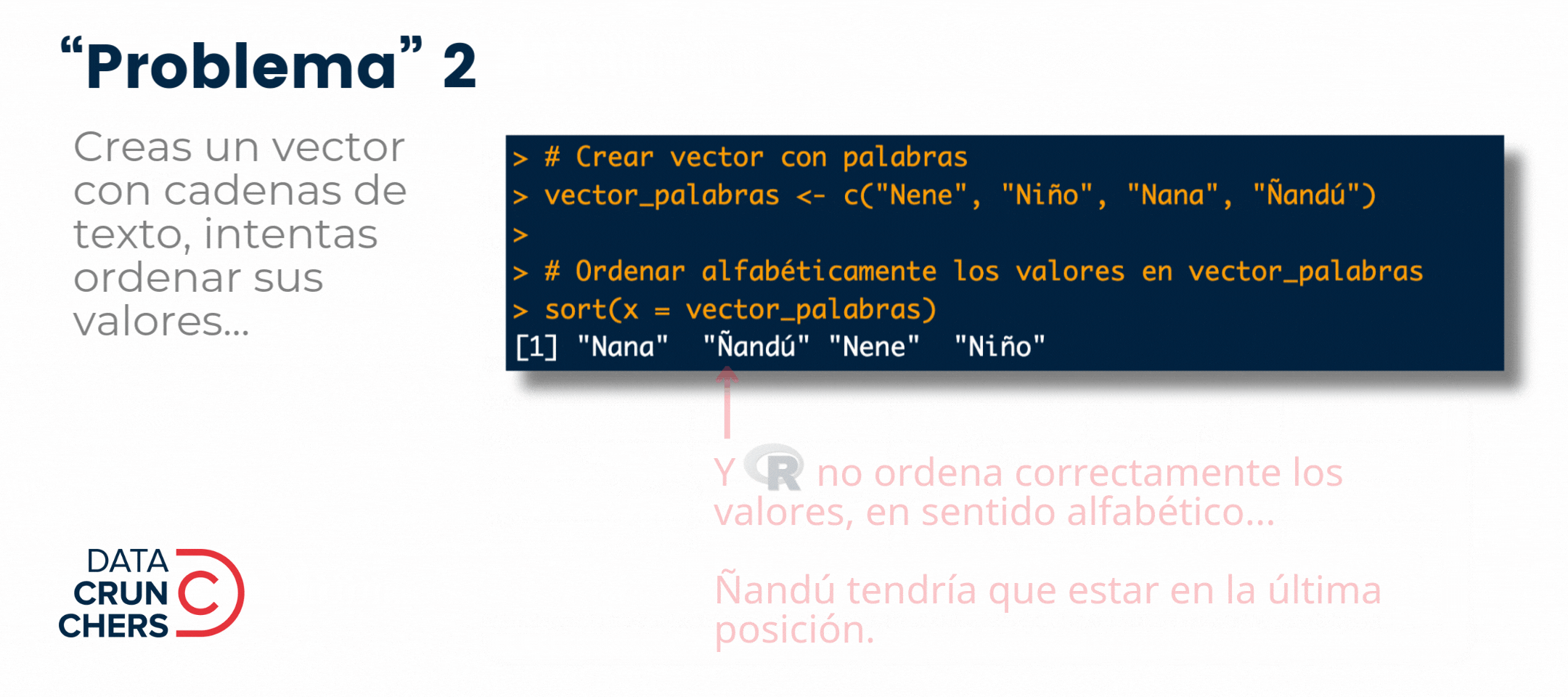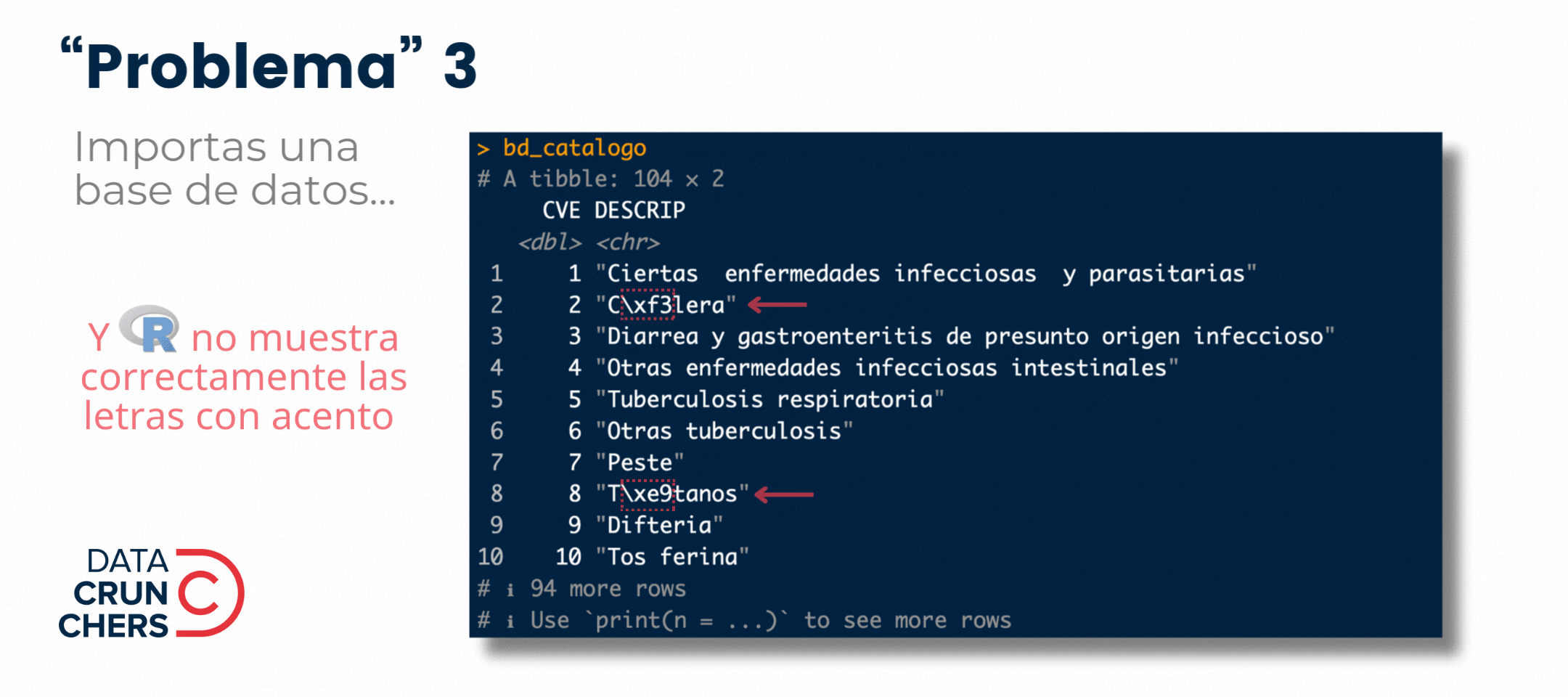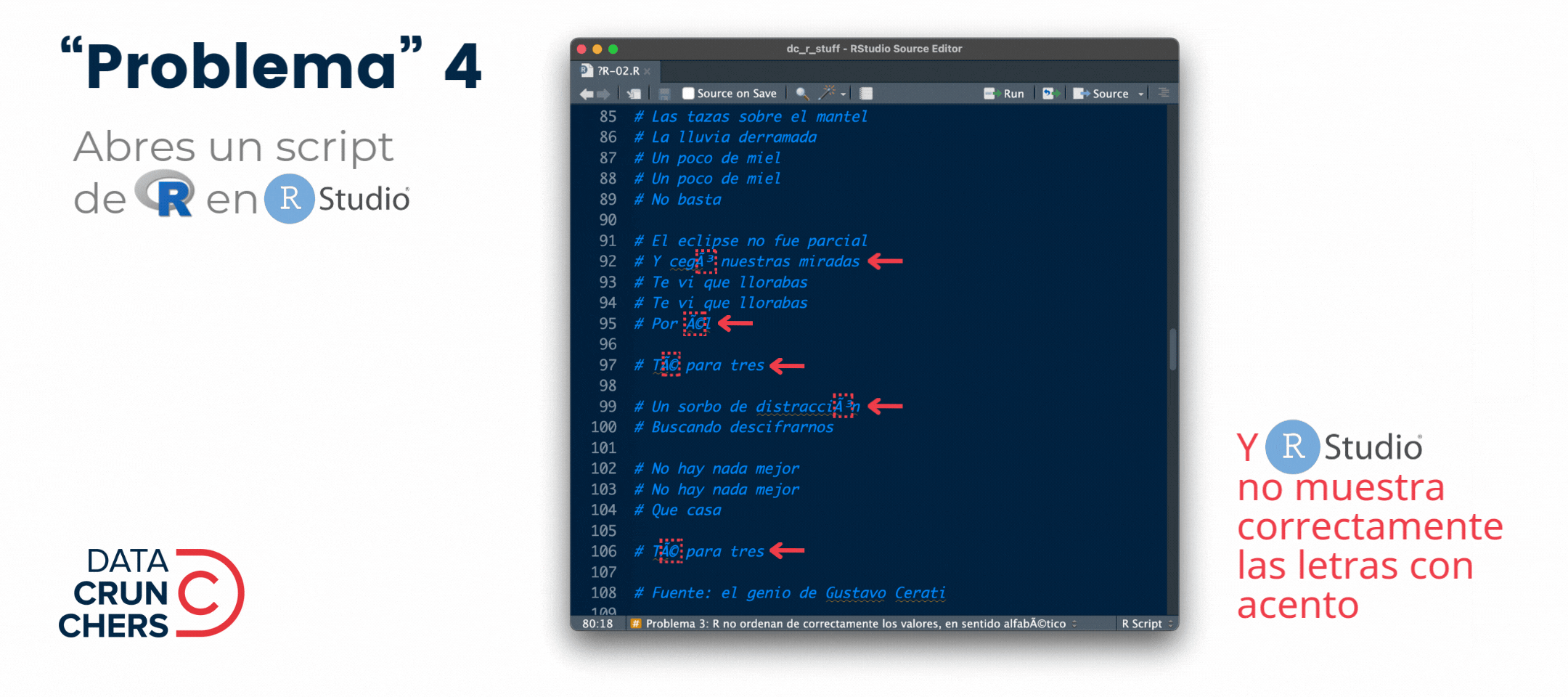
Todos están determinados por el
locale (de tu equipo, de
R y/o de RStudio) 😮.
A esto dedicaremos el newsletter de esta y la siguiente semanas.
El locale es el conjunto de reglas que permiten que las computadoras y programas que utilizamos se ajusten a las convenciones de cierto idioma, país y cultura, y, con ello, tropicalizar nuestra experiencia al usarlos.
En la práctica, el locale define una larga lista de valores que nuestros equipos y (algunos) programas utilizan cuando tienen que:
-
Determinar qué formato usar para representar fechas (p. ej., January vs. enero, YYYY-MM-DD vs. MM-DD-YYYY)
-
Representar números (p. ej., 1,234.56 vs. 1.234,56)
-
Clasificar caracteres (p. ej., letras dígitos, espacios) y lidiar con caracteres especiales (p. ej., acentos, virgulilla)
-
Ordenar alfabéticamente los valores de una variables tipo cadena de texto
-
Trabajar con valores monetarios (p. ej., tipo de moneda, símbolo)
La respuesta depende, entre otras cosas, del sistema operativo de tu equipo (p. ej., Mac/Linux o Windows) y la versión del mismo.
Por suerte, puedes responder esta pregunta sin salir de R.
A continuación encontrarás dos opciones de código: la primera es útil si el sistema operativo de tu computadora es Mac o Linux, y la segunda si corre en Windows.
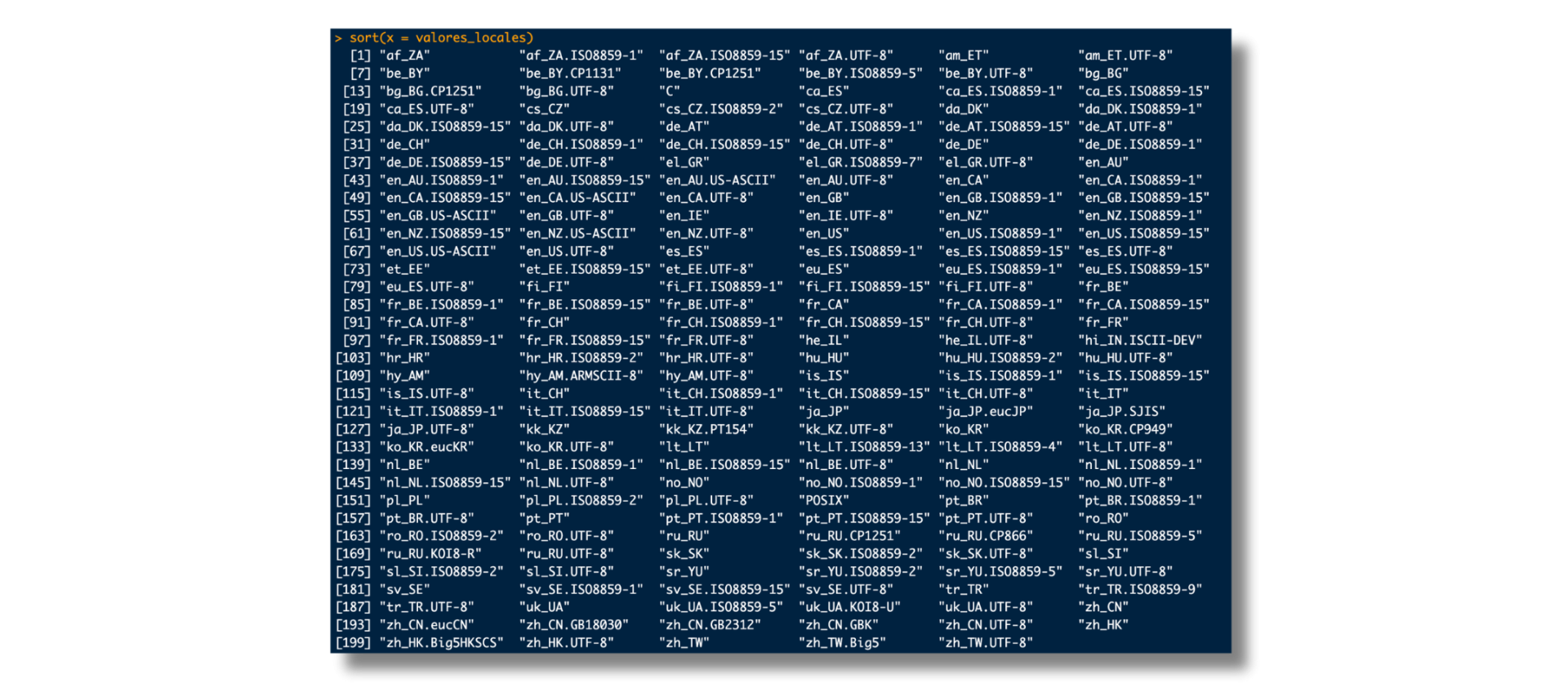
Si copias y ejecutas el código de arriba en R, deberías ver algo como esto en tu consola:
En mi caso, esta lista contiene los poco más de 200 locales disponibles en mi equipo 🤯, y que representan los que puedo usar en una sesión de R.
Por favor nota que el nombre de casi todos está compuesto, como mínimo, por dos componentes separados por un guión bajo ("_").
Mientras que el primero define el idioma que se debe usar (p. ej., "en" para inglés), el segundo establece la región o país (p. ej., "GB" para Gran Bretaña). Si eligiera el locale "en_GB" en mi computadora, entonces trabajaría en inglés con las convenciones de Gran Bretaña (p. ej., colour en lugar de color).
La imagen de arriba también muestra que los nombres de algunos locales tienen un tercer componente, separado por un punto (".") del resto (p. ej., "en_GB.UTF-8").
Este último elemento le indica a nuestra computadora qué codificación de caracteres utilizar (regresaré a este tema la próxima semana).
Nota bene
OJO 1: La lista de locales de mi computadora sólo incluye cuatro opciones que usan el idioma español ("es_ES", "es_ES.ISO8859-1", "es_ES.ISO8859-15" y "es_ES.UTF-8") y todas corresponden al español de España. En consecuencia, aunque lo quisiera, no podré usar un locale en R para español de México (e.g., "es_MX").
OJO 2: Si el sistema operativo de tu equipo es Windows, aunque el segundo y tercer componentes también estarán separados por "_" y ".", la sintaxis de los nombres de los locales puede ser diferente.
Si nuestras computadoras tienen decenas y decenas de locales disponibles, ¿cuál usa R?
Por suerte, el código para averiguarlo es mucho más sencillo que en el caso anterior.
Basta con que ejecutes la siguiente función en R para averiguarlo:
Al hacerlo, deberías ver algo como esto en la consola:

Notoriamente, R me está avisando que usa el locale llamado en_US.UTF-8.
¿Pero por qué repite tantas veces ese valor?
Con ello, R me indica que está usando el mismo locale para determinar los valores de todas las categorías que mencioné antes: formato de fechas, representación de números, etc.
Éste es el default, pero no tiene que ser así, pues podemos configurar cada una de estas categorías con diferentes locales.
Y eso nos lleva a los recursos de la semana 👇...