Buen día colega.
Es martes de ?R 🤓.
La semana pasada me clave duro en el locale: ese conjunto de reglas que permiten que nuestras computadoras y programas se ajusten a las convenciones del idioma, país y cultura que queramos (dentro de ciertos límites).
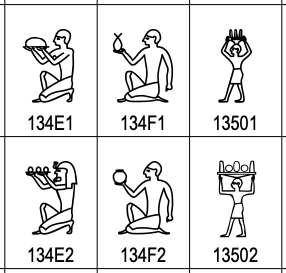
En el camino, expliqué cómo resolver los primeros dos "problemas" que aparecen en este👇 gif:
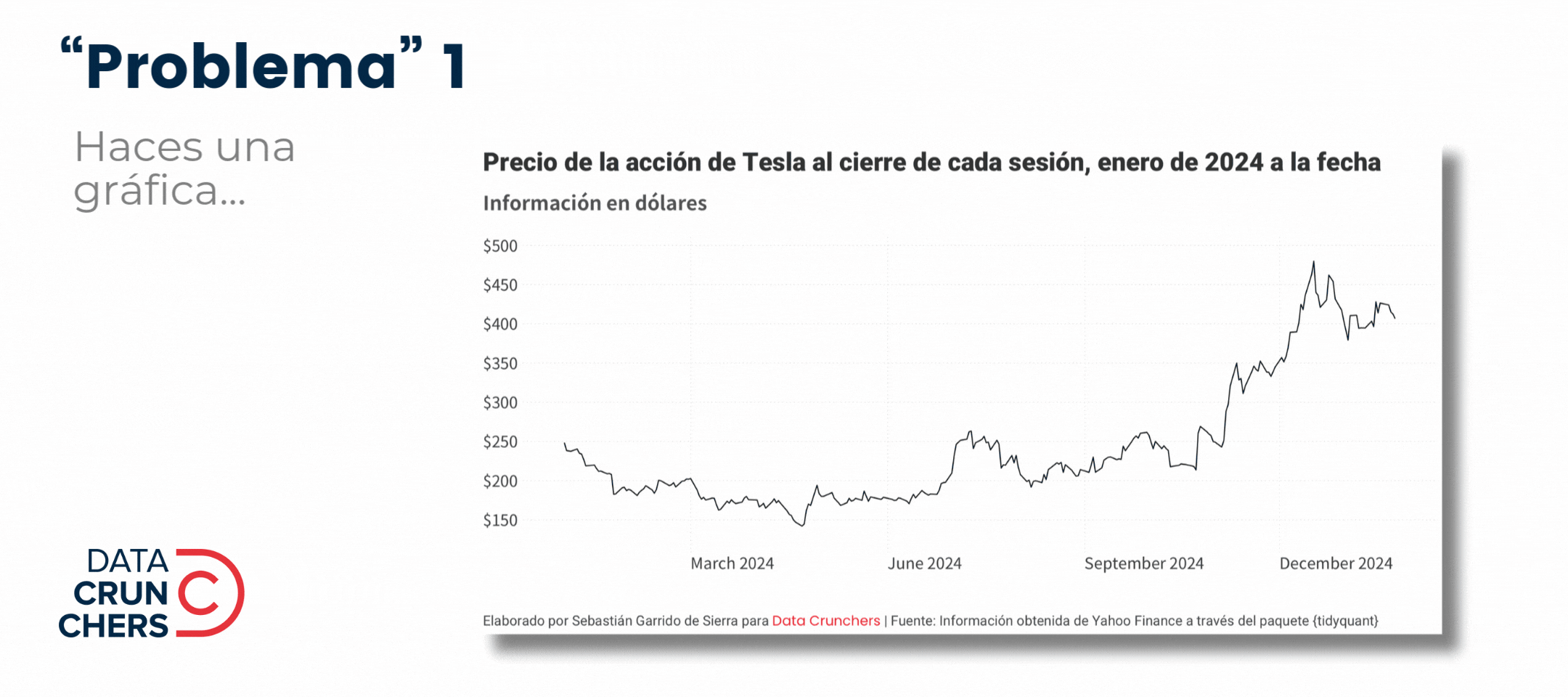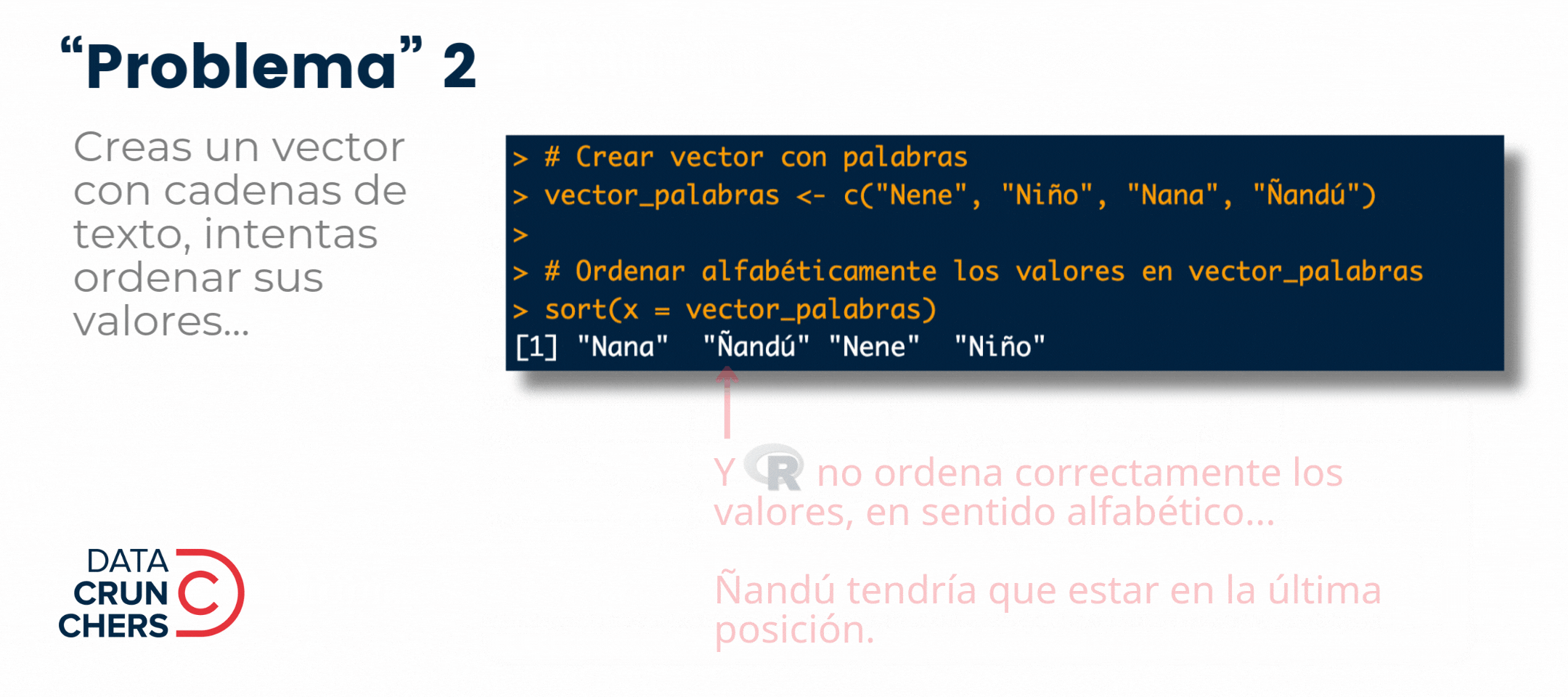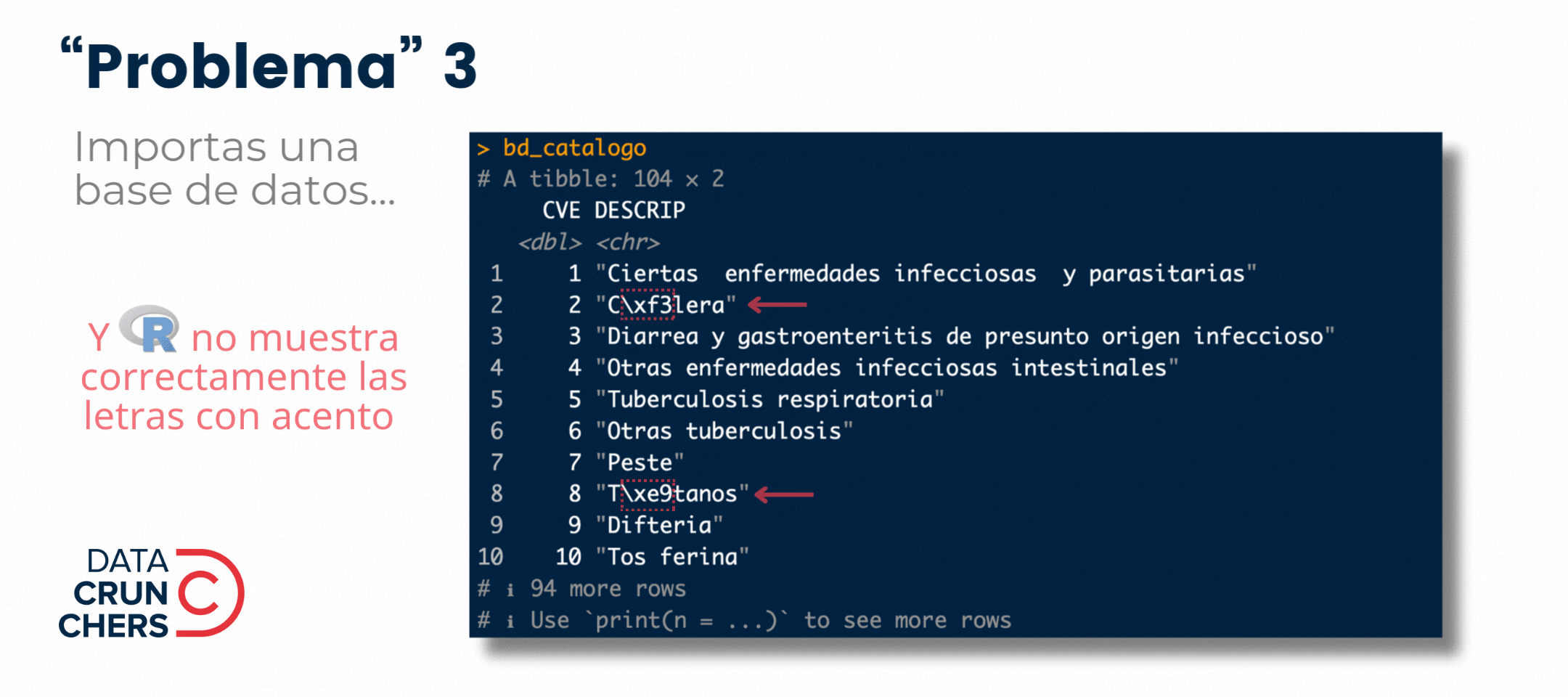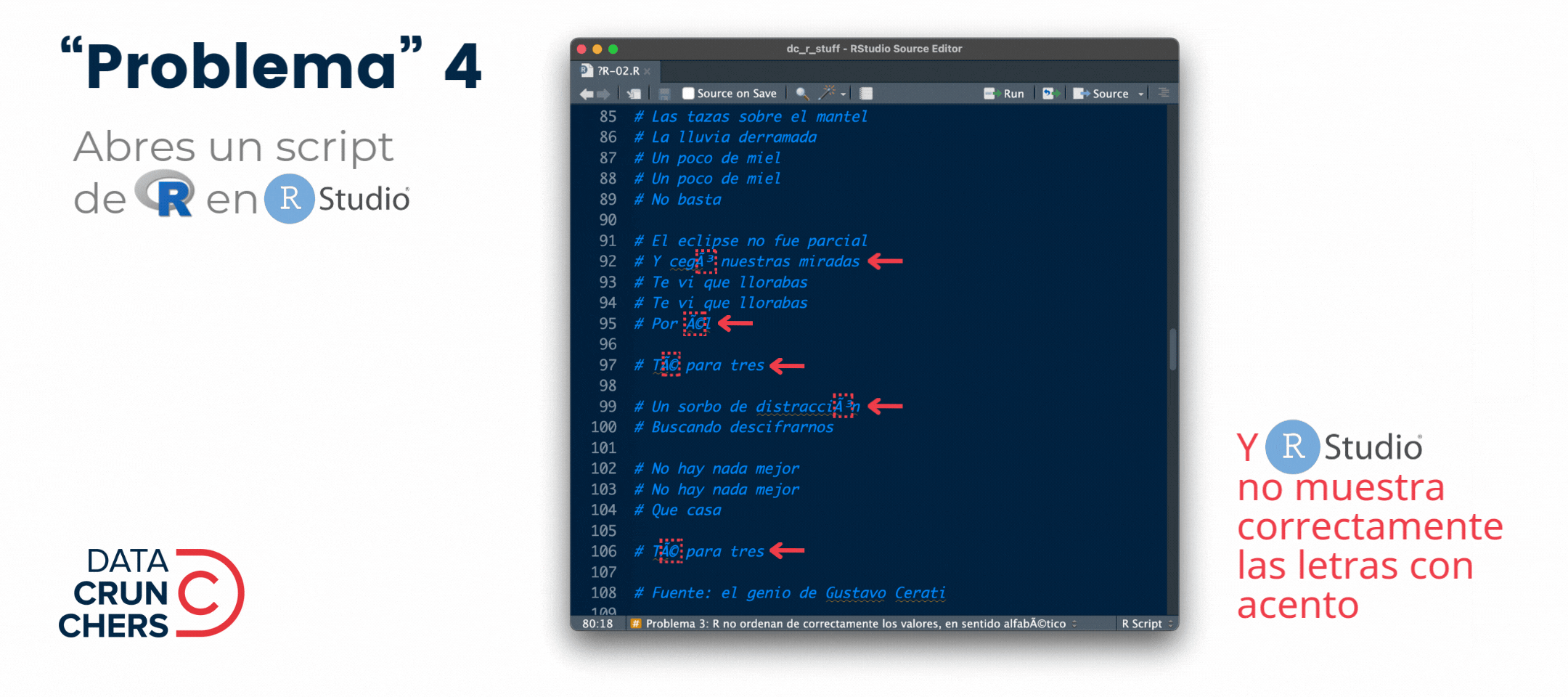
Y dejé los dos últimos para esta semana porque su origen y solución es similar: dependen de la codificación de caracteres o encoding que se use al importar un archivo y/o abrir un script de R en RStudio.
De eso trata el número de hoy.
A darle.
La codificación de caracteres o encoding es un método para representar, almacenar y transmitir caracteres a través de secuencias de símbolos físicos o digitales.
Durante décadas, las tarjetas y cintas de papel perforadas fueron los principales medios para realizar este tipo de codificación en el mundo de la computación y las telecomunicaciones.
La siguiente foto muestra una de estas cintas...

... y en este video puedes ver cómo se creaban y utilizaban.
Nota bene
Por fa nota cómo la persona que aparece en el video, primero usa el comando punch (perforar) para almacenar una instrucción en la cinta de papel, y después ejecuta el comando load (cargar) para que la computadora lea y ejecute la instrucción guardada en la cinta 🤯.
La tecnología para codificar caracteres comenzó a cambiar a mediados del siglo XX, gracias a la invención de los sistemas de almacenamiento magnético.
A partir de ese momento, el guardado y procesamiento de caracteres se trasladó progresivamente a medios digitales, utilizando bits y bytes para almacenar cualquier letra o símbolo mediante una combinación única de 0s y 1s.
Éste es el método que perdura hasta hoy.
A pesar del enorme brinco tecnológico que significó esta innovación, las primeras codificaciones digitales fueron diseñadas para representar, almacenar y transmitir los caracteres de lenguajes naturales específicos, (p. ej., coreano, hebreo, inglés), y los símbolos técnicos y científicos de ciertos países (p. ej., Estados Unidos, China).
Como resultado, muchos de estos esquemas de codificación eran incompatibles entre sí, provocando que las computadoras de una región/país interpretaran incorrectamente uno o más de los caracteres registrados por los equipos en otra región/país.
Estos problemas se han reducido considerablemente gracias a la creación de formatos de codificación que incluyen los caracteres de un enorme conjunto de lenguajes naturales y miles de símbolos.
Uno de ellos es el 8-bit Unicode Transformation Format, o UTF-8, un formato de codificación de caracteres que nos permite representar cualquiera de los casi 155 mil caracteres y símbolos definidos por el estándar Unicode, mismo que abarca 168 sistemas de escritura, e incluye miles de jeroglíficos egipcios como estos: Si bien la creación de UTF-8 y otros ambiciosos formatos de codificación de caracteres ha permitido que las computadoras se "entiendan" cada vez mejor, en la práctica, cada tanto ocurre algo como lo que ilustran los dos problemas que dejé pendientes la semana pasada:
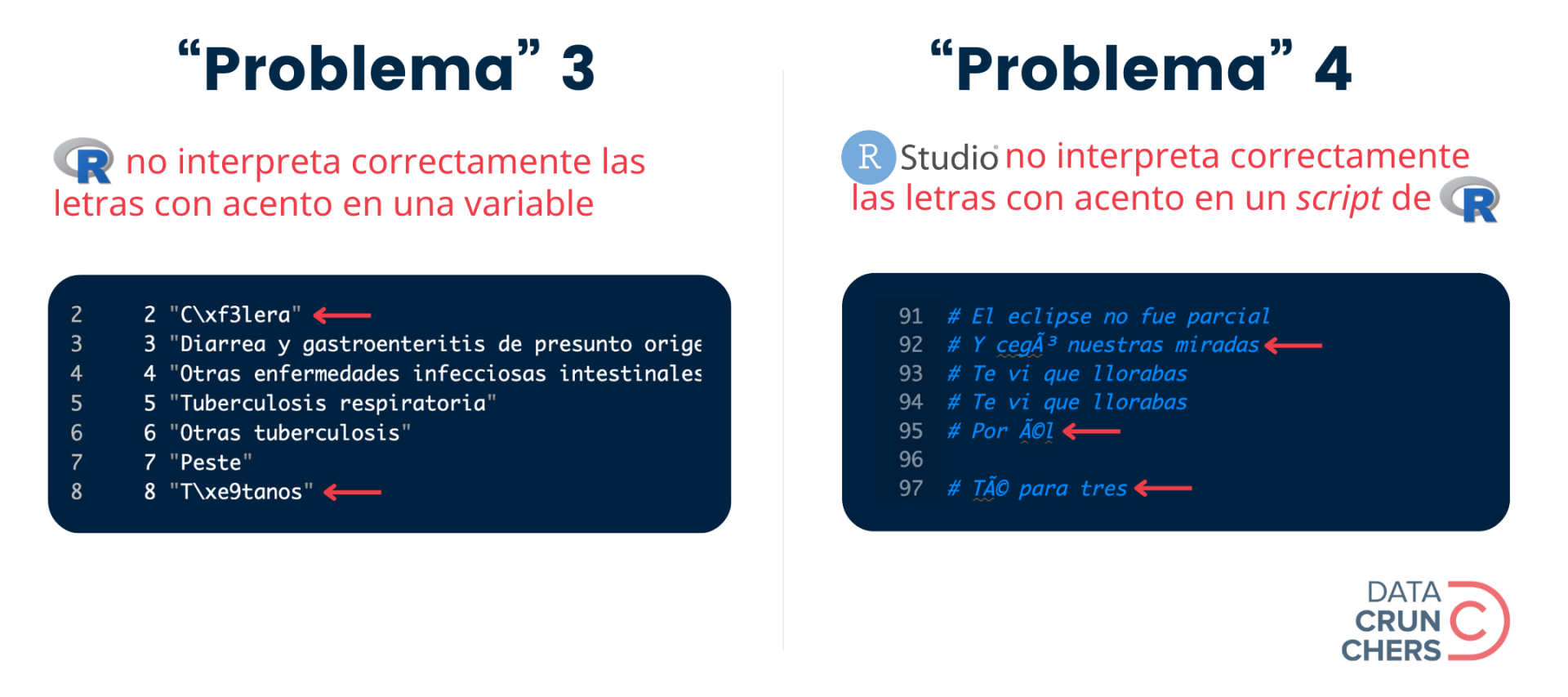
En ambos casos, la aparición de esos caracteres extraños (p. ej., \xf3 o ó) se debe a que la configuración de una partecita del locale de la computadora o el programa que generó el archivo (aquella que define el encoding), es diferente a la del equipo o aplicación que intenta leerlo e interpretarlo.
Tomemos como ejemplo el "problema" 3.
Éste surgió después de que usé la función read_csv() del paquete {readr} para importar esta base de datos, misma que fue almacenada por el INEGI en un archivo de formato .csv, y que contiene la lista de posibles causas de mortalidad definidas por la Organización Mundial de la Salud (OMS).
Por default, la función read_csv() asume que los caracteres y símbolos guardados en el archivo que vas a importar fueron codificados con el formato UTF-8. Si esto no es así, como en este caso, R no podrá interpretar correctamente ciertos caracteres especiales (p. ej., letras con acento o diéresis).
En términos generales, la solución consiste en modificar el encoding del programa que estás usando para que sea compatible con la codificación de caracteres utilizada por la persona o institución que generó el archivo en primera instancia.
Cómo llevar esto a la práctica, dependerá del programa que estés usando y/o la tarea que estés realizando.
Si la incompatibilidad de encodings surgió al importar archivos de texto plano a R con una de las funciones de {readr}, como en el "problema" 3, la solución consiste en modificar el valor que tiene por default el argumento locale en la respectiva función.
A continuación verás dos opciones de código:
Mientras que en la primera se usa el valor por default del locale (que implica, entre otras cosas, usar UTF-8 como encoding), en la segunda le indicamos a R que debe usar el formato latin1 con el código locale = locale(encoding = "latin1").
Nota bene
OJO: Aquí usé latin1, o ISO 8859-1 Western Europe, porque junto con UTF-8, latin2 y latin3, es uno de los formatos de encoding más usados al generar archivos en países hispanohablantes.
¿Pero qué pasa cuando no sabes qué encoding fue utilizado al crear la base de datos que quieres importar a R? 😮
Sufrir no debes tú (Yoda dixit). En los recursos de esta semana 👇 te cuento cómo lidiar con esta incertidumbre.
Por otro lado, si la incompatibilidad de encodings se presenta al abrir un script de R en RStudio, como en el "problema" 4, entonces debes seguir los pasos que ilustro en este gif:
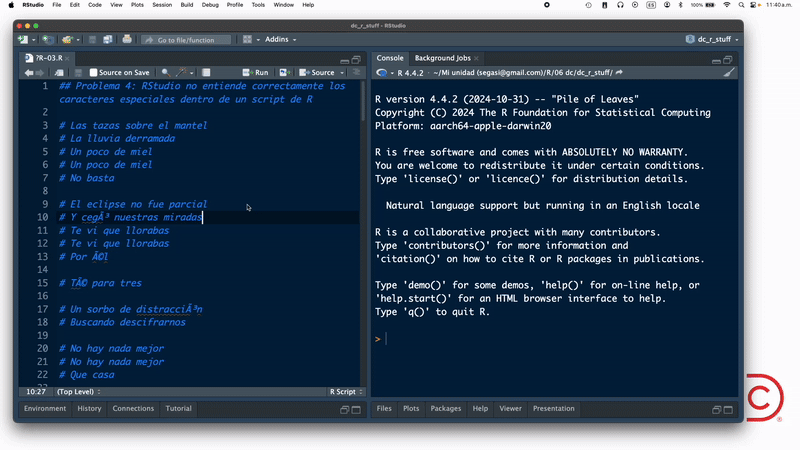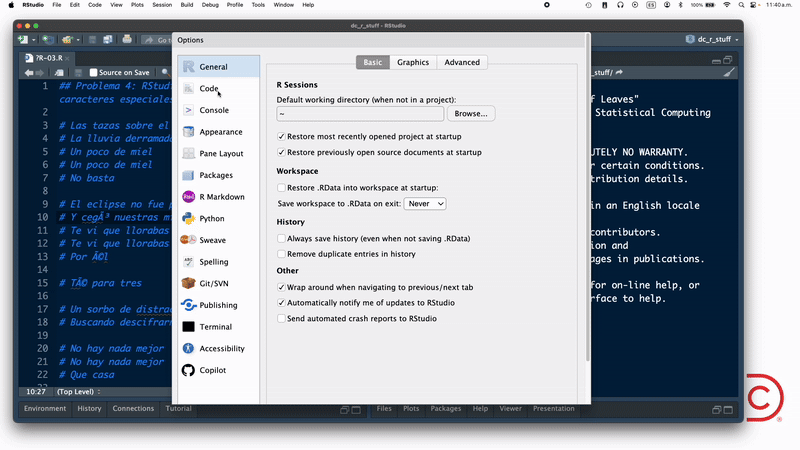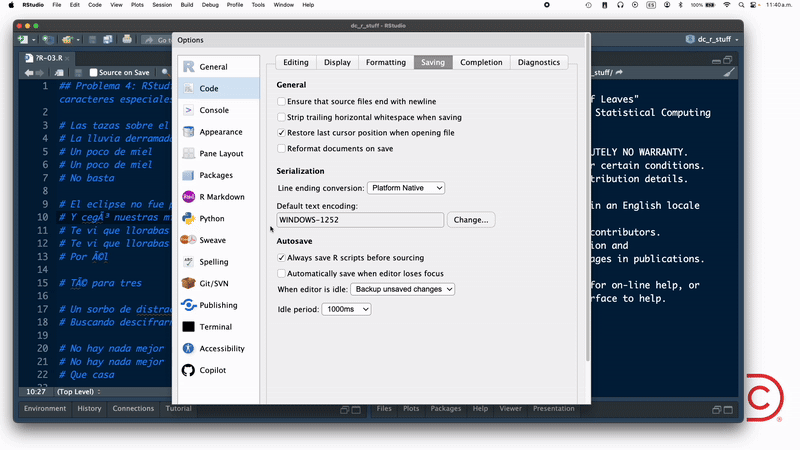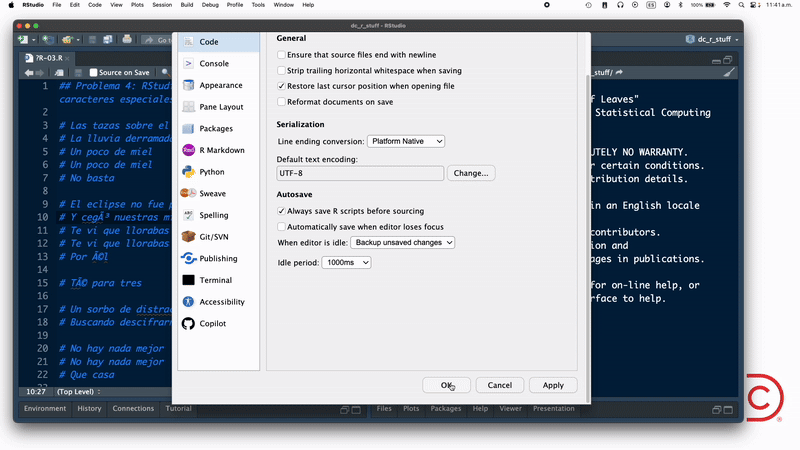
En este ejemplo elijo UTF-8 como encoding porque sabía que esa era la codificación de caracteres que usó la persona que creó el script (yo merol).
En tu caso, es probable que no tengas ese pedazo de información, pero en la siguiente sección te explico cómo "adivinar" el encoding de cualquier archivo de texto plano.