Es inevitable.
Más temprano que tarde, los NAs aparecen y complican nuestra vida al trabajar en R.
A veces están ahí, visibles y campantes, después de importar una base de datos.
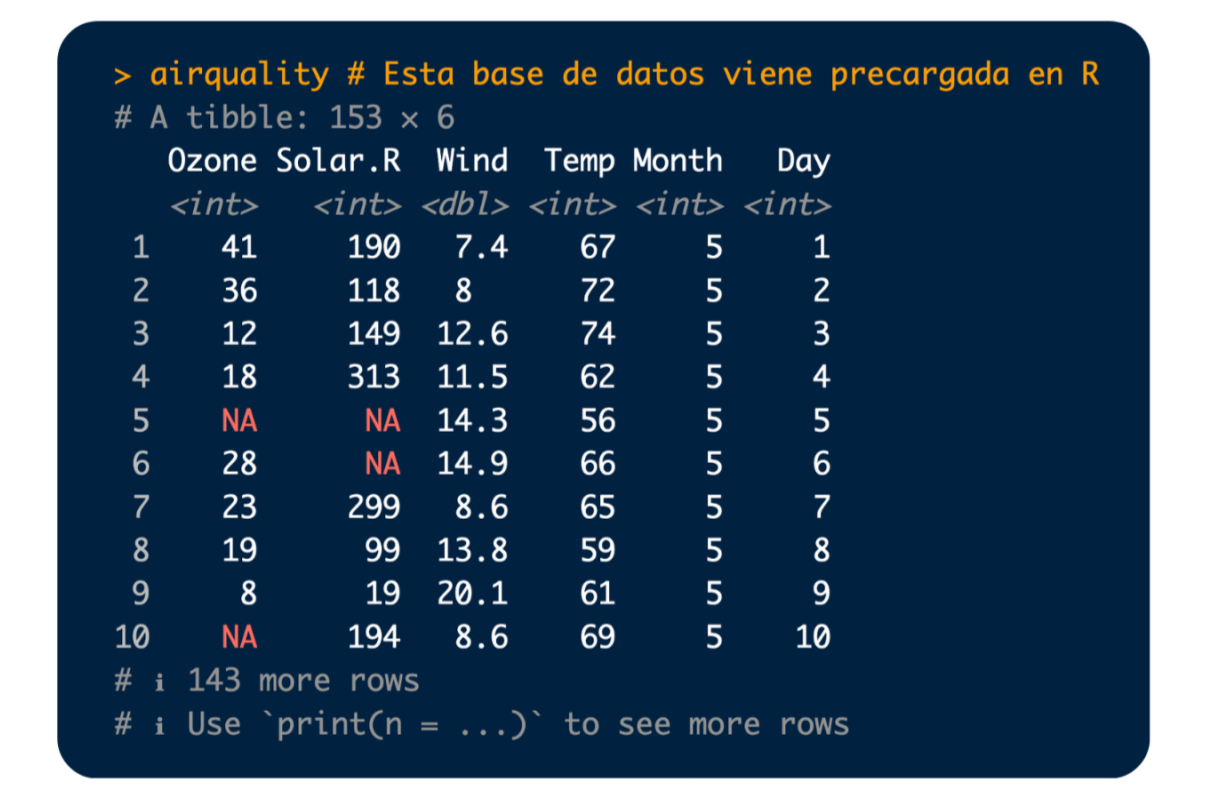
Por ejemplo, si copias y ejecutas el siguiente bloque de código:
... deberías ver algo como esto:
Otras veces se esconden en los renglones que no ves, esperando la oportunidad para "contagiar" los resultado de las operación aritméticas que realices o impedirte ajustar un modelo.
Puedes confirmar lo que digo si copias y ejecutas los siguientes pedazos de código:
Ahh... Que especiales y (potencialmente) desquiciantes son los NAs en el mundo de R.
Y a pesar de esto, qué poco nos explican sobre cómo lidiar con ellos.
Al menos ese fue mi caso.
Tardé años, literalmente años, en entender cómo trabajar de forma adecuada con NAs.
Esto no debería ser así, por lo menos no para quienes formamos parte de la comunidad de Data Crunchers 🤓.
Por ello, durante los últimos días me puse a recopilar todos los consejos y recursos que conozco para entender y lidiar de forma productiva con los NAs.
Durante éste y (cuando menos) el siguiente número de ?R te compartiré lo que, por no encontrar un mejor nombre, llamaré la guía básica para trabajar con NAs en R (y no morir en el intento).
A darle.
En un mundo ideal, deberíamos trabajar con bases de datos integradas por variables en las que todos sus valores están claramente definidos.
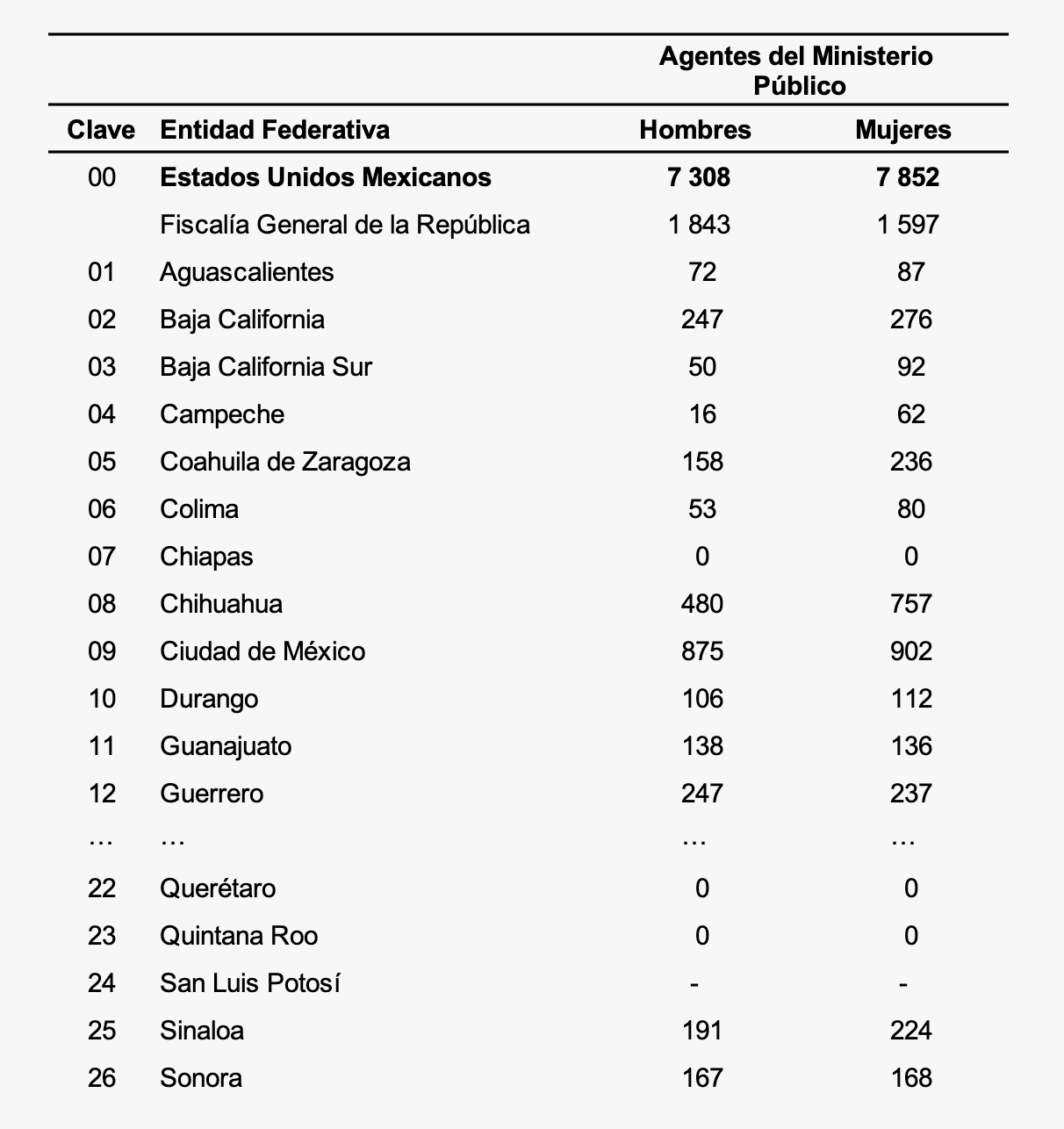
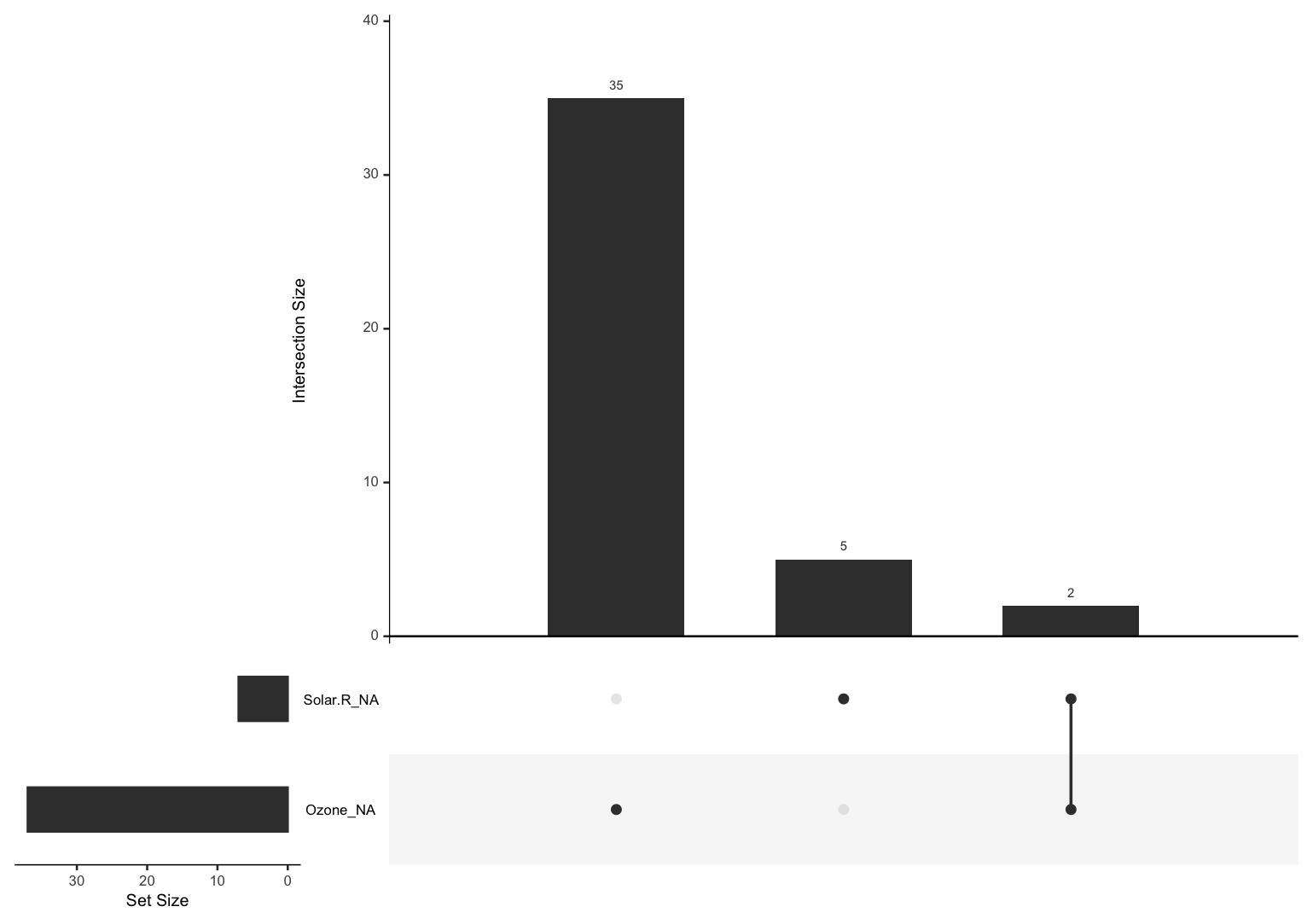
Por desgracia, la realidad suele pensar diferente y nos ofrece bases de datos como esta:
Fuente: Extracto de la base de datos incluida en la hoja 7 del tabulado básico "Estructura organizacional y recursos" del Censo Nacional de Procuración de Justicia Estatal 2023 del INEGI. URL: https://tinyurl.com/5n99h35f
En las dos últimas columnas el valor de San Luis Potosí es "-".
En términos técnicos, esto se conoce como un valor faltante y es la forma en que registramos lo desconocido (*se puso filosófico el viejo Segasi*).
Existen diversas convenciones para representar los valores faltantes de una variable.
Mientras que en Python se utiliza None y en Stata el símbolo ".", en R usamos dos letras, NA, mismas que significan not available o no disponible.
Nota bene
Por favor nota que en R NA es diferente a "NA", NaN y NULL.
El primero representa un valor faltante. El segundo, una cadena de texto integrada por las letras mayúsculas N y A, el tercero es el valor not a number, y el cuarto el valor nulo.
Dados los retos y complejidades que suelen generarnos los NAs al analizar una base de datos, es inevitable preguntarse por qué existen.
Explicaciones hay muchas. Aquí me concentro en tres.
1) Algunas bases de datos incluyen valores faltantes porque la persona o institución encargada de proporcionar un pedazo de información, se negó a hacerlo.
Por ejemplo, en la tabla que incluí en la sección anterior, los valores faltantes se deben a que las autoridades de San Luis Potosí consideraron que la información solicitada por el INEGI era de carácter reservado, y no se la proporcionaron.
2) También es común que una base de datos incluya valores faltantes porque el instrumento utilizado para medir un fenómeno se descompuso.
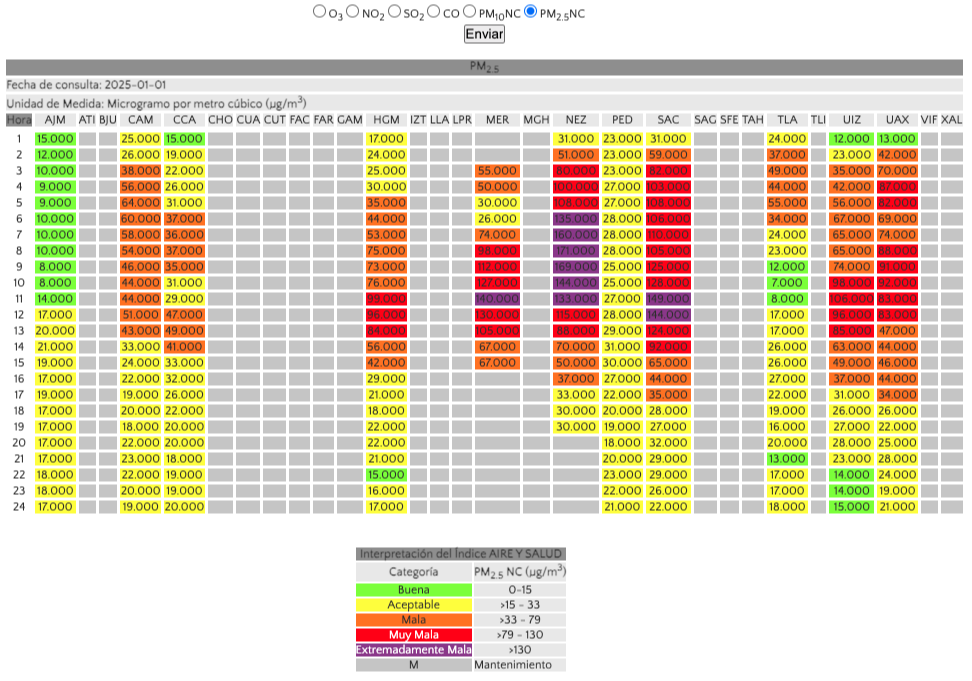
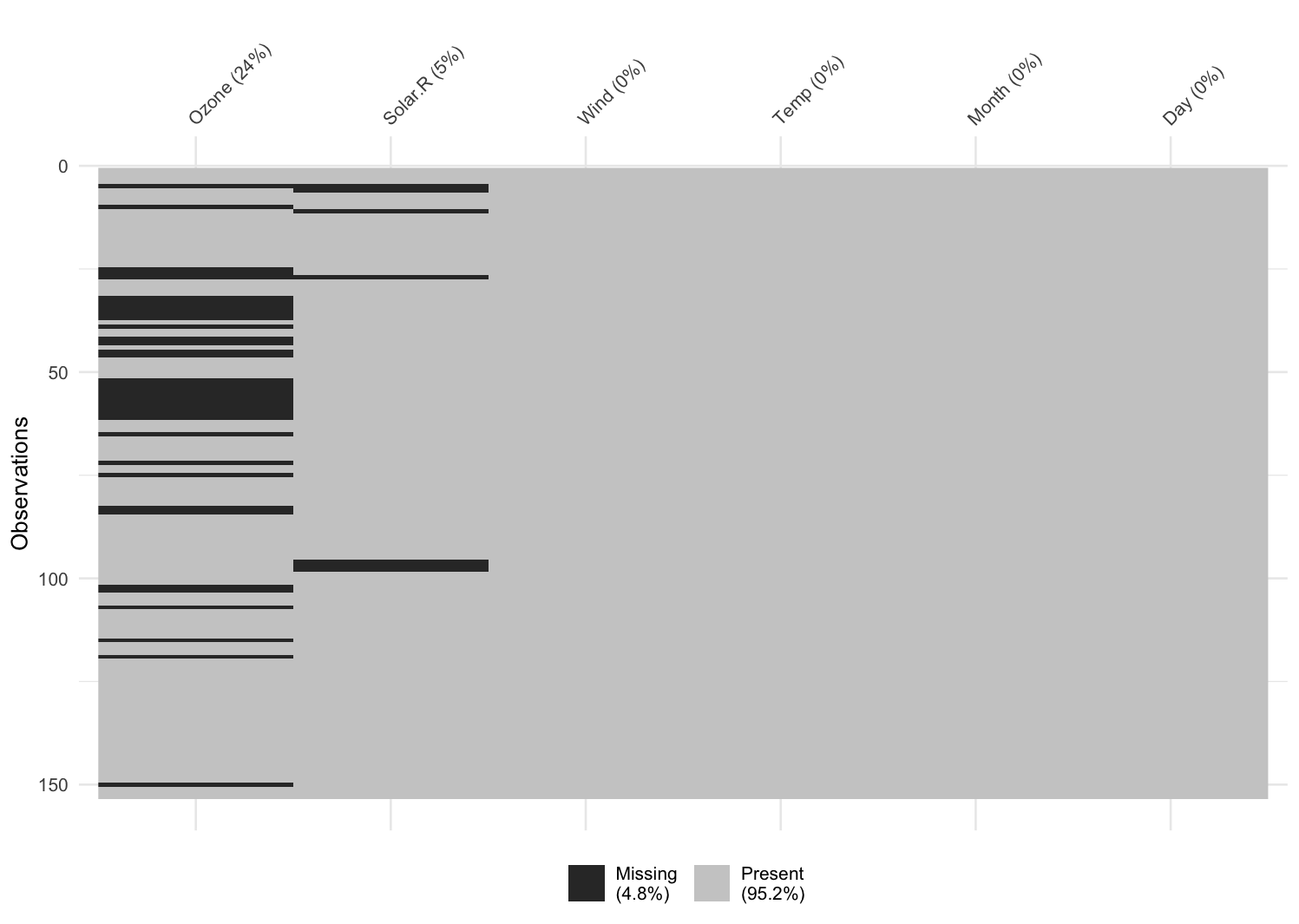
Por ejemplo, la siguiente imagen muestra las mediciones de partículas menores a 2.5 micrómetros (PM2.5) en la Zona Metropolitana del Valle de México el 1 de enero de 2025:
De acuerdo con la leyenda que está en la parte de abajo, todas las celdas en gris oscuro representan valores faltantes, ya que el instrumento que debía medir el nivel de este contaminante estaba en "mantenimiento".
3) En otras ocasiones los valores faltantes surgen después de unir dos bases de datos que si bien estaban "completas" de forma individual, al unirlas provocamos que a una o más variables les falten valores.
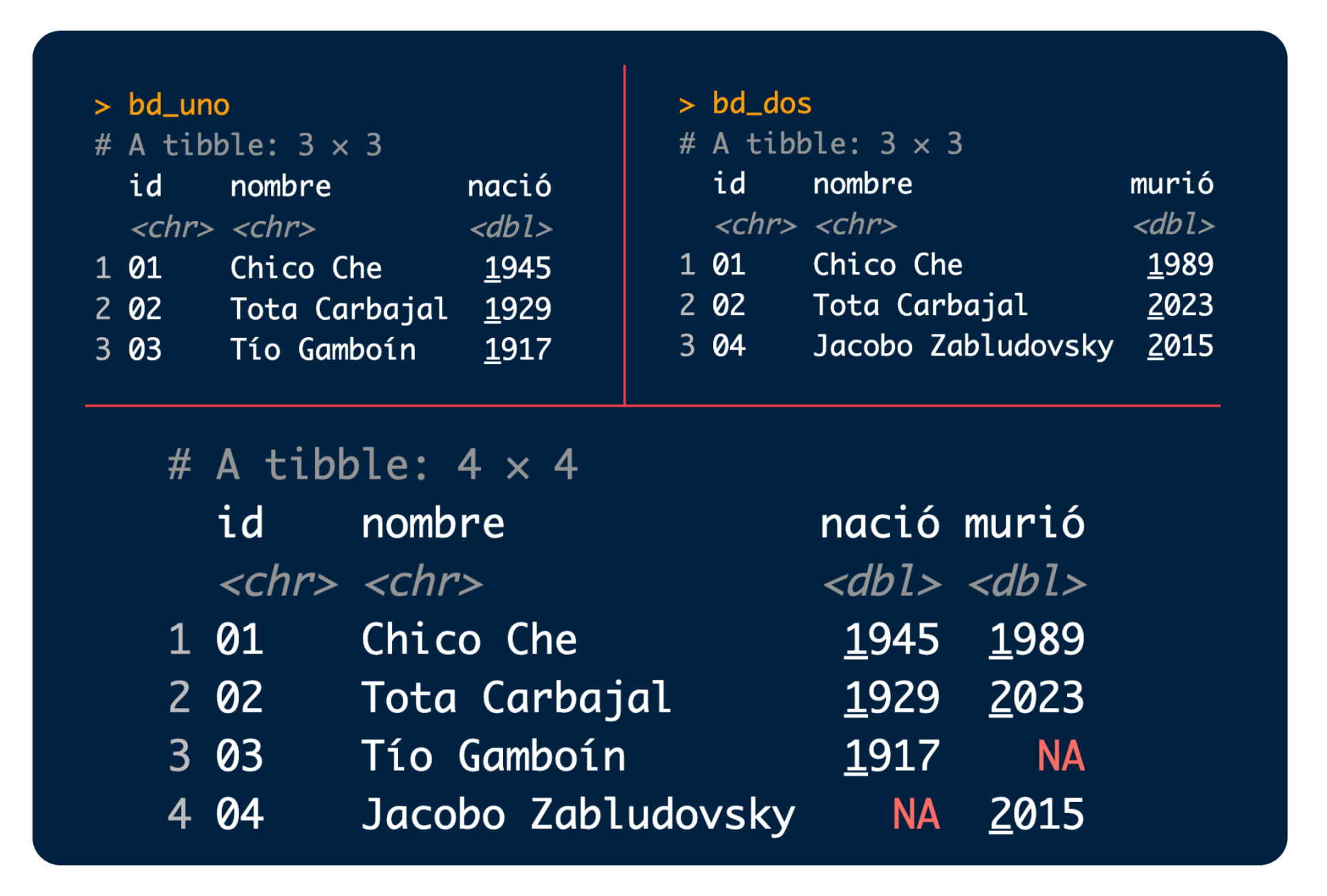
Por ejemplo, si copias y ejecutas los siguientes bloques de código:
... en el proceso primero deberías ver las dos bases que están en el primer renglón de la siguiente imagen, y al final la que está debajo:
Parte de la respuesta tiene que ver con lo que comenté al comienzo de este correo:
-
Los NAs son "contagiosos" y provocarán que los resultados de las operaciones aritmética que hagas con una variable que incluye uno o más, también sea NA
-
La presencia de NAs en una o más variables de una base de datos puede provocar que R nos impida usar ciertas funciones (p. ej., kmeans())
En consecuencia, el primer motivo por el cual creo que debería interesarte aprender a lidiar con NAs es entender cómo enfrentar y resolver estos retos comunes.
El segundo motivo es más sutil.
Existen diversas estrategias para lidiar con NAs y no siempre es evidente cuál utilizar en cada caso.
El riesgo entonces es que al elegir el camino equivocado, termines generando un problema más grande que el que intentabas resolver.
Pero para llegar ahí, primero tenemos que hablar de cómo saber si una variable o base de datos tiene NAs.
Así que termino esta semana compartiéndote algunos recursos 👇 para detectar la presencia de valores faltantes y dimensionar la gravedad del problema.