La semana pasada propuse que dedicaría este número de ?R a explorar diversas estrategias para lidiar con los NAs o valores faltantes.
Voy a cumplir, lo prometo, pero lo haré en dos parcialidades.
El motivo es simple y complejo a la vez.
Mientras escribía la primera versión de este texto, me di cuenta que para explicar de mejor forma cuándo y por qué elegir cierto tipo de estrategias para lidiar con NAs, primero tenía que profundizar un poco más sobre los tres grandes tipos de valores faltantes que existen, así como qué los definen/distinguen entre sí.
Así que esta semana abordaré las características de los valores faltantes...
-
Completamente aleatorios o Missing Completely At Random (MCAR)
-
Aleatorios o Missing At Random (MAR)
-
No aleatorios o Missing Not At Random (MNAR)
... y la próxima me concentraré en las diferentes alternativas que tenemos para trabajar en R con (o a pesar de) ellos.
Aun con este cambio de planes, en la posdata de este correo👇 comienzo a cumplir lo que propuse hace unos días.
La teoría de la cual se derivan los tres tipos de valores faltantes que enlisté arriba, parte de un supuesto: cada valor dentro de una variable en una base de datos tiene cierta probabilidad de faltar.

Cuando esa probabilidad es la misma para todas las observaciones de todas las variables que integran nuestra base de datos, decimos que los valores faltantes son completamente aleatorios o Missing Completely At Random (MCAR) en inglés.
En la práctica, esto significa que los factores que provocaron que uno o más valores falten en una base de datos, no tienen relación ni con las variables que incluye la base, ni con otros factores desconocidos.
¿Cuándo podría ocurrir esto?
Va un ejemplo.
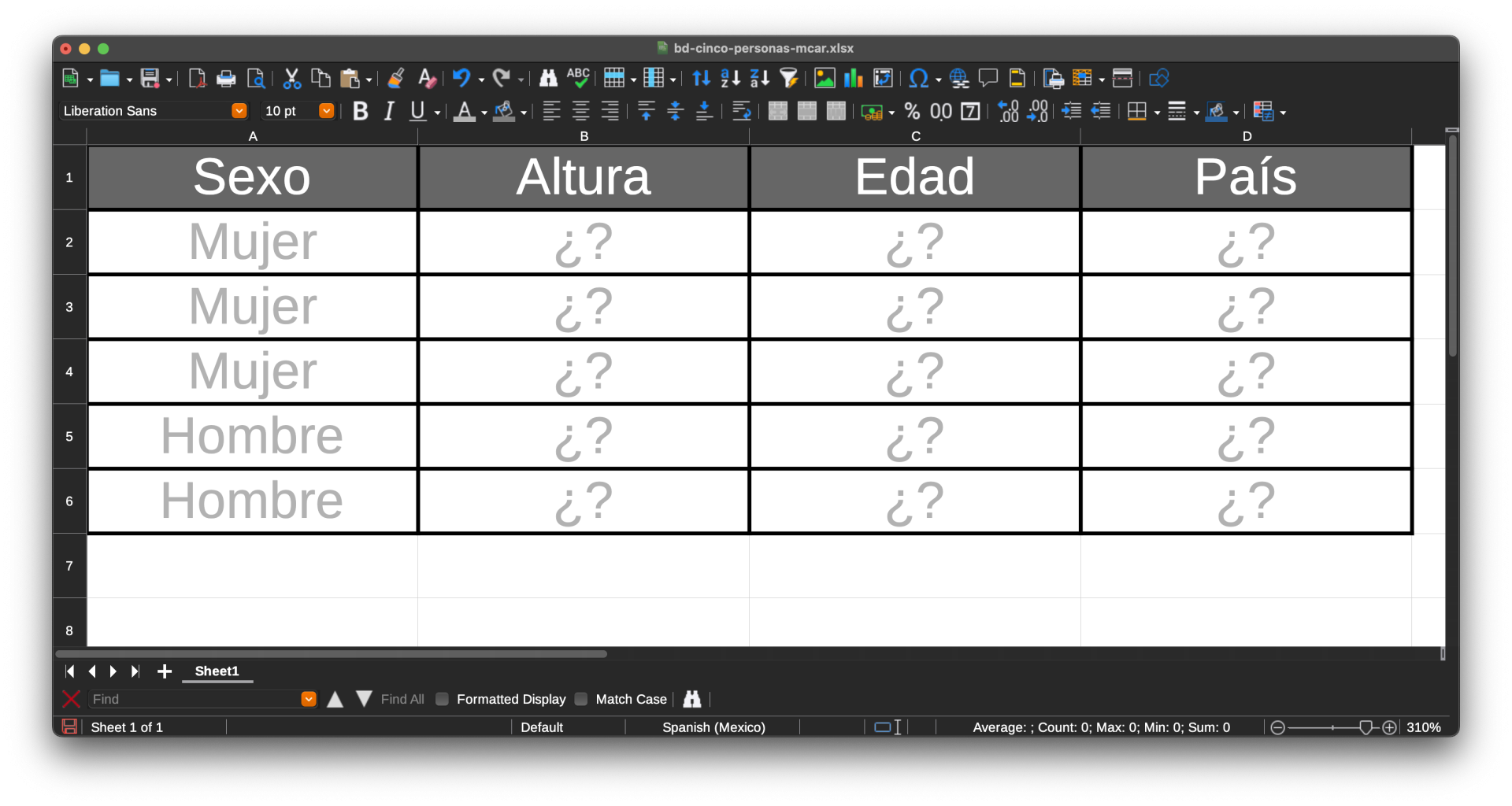
Imagina que tienes una hoja de cálculo y en ella debes construir una base de datos con la información de cinco observaciones (o renglones) para cuatro variables (o columnas).
La primera variable registra el sexo de cada persona. Es la única variable para la cual conoces los valores desde el principio.
En la segunda columna debes registrar la altura de cada persona, en la tercera su edad y en la cuarta el país en el que viven.
Las cinco personas existen, por lo que ellas saben cuál es su altura, edad y país de residencia.
Pero para que tú puedas conocer cada uno de los valores de las tres últimas columnas, debes "echar" un volado con una moneda perfectamente balanceada (es decir, la probabilidad de que la moneda caiga de un lado u otro es exactamente de 50%).

En total debes echar 15 volados (cinco por columna).
Si la moneda cae en Sol, podrás conocer el valor de la celda correspondiente. Si cae en Águila, nanai: el valor será faltante (disculpa los mexicanismos si no eres de por acá).
Nota bene
Por favor nota que el usar volados con una moneda balanceada para conocer los valores de cada columna, implica que ninguna característica de la persona —ni su sexo, ni su altura, ni su edad, ni su país de residencia — influye en si falta o no un valor.
Entonces echas los 15 volados y registras la información que logras obtener. Si terminas con uno o más valores faltantes, estos serán completamente aleatorios.
Cuando se trata de lidiar con NAs, éste es el menos malo de los mundos.
Si tu análisis omite este tipo de valores faltantes, no incurrirás en un sesgo sistemático; el impacto se "limitará" a la reducción de la información (que en sí mismo puede ser un problema importante).
Por desgracia, como tantas otras cosas en la vida, si bien este es el tipo de valores faltantes con los que nos gustaría lidiar cotidianamente, es poco probable que los que encontremos en nuestra base de datos sean de este tipo 😢.
Eso nos obliga a preguntarnos qué pasa cuando los valores faltantes sí dependen de una o más variables en la base de datos.
Pasemos a los valores faltantes aleatorios.
Regresemos a una versión ligeramente modificada del ejemplo que propuse arriba.
De nueva cuenta:
-
Debes construir una base de datos en la que quieres registrar la altura, edad y país de residencia de cinco personas
-
Al comienzo, sólo conoces el sexo de cada una
-
Las personas existen y saben su respectivo valor para las otras tres variables
-
Para conocer cada valor de las tres últimas columnas, debes "echar" un volado
La diferencia crucial es esta: en lugar de usar una sola moneda perfectamente balanceada (50%-50%), tienes que utilizar dos monedas, una para cada sexo.
La moneda que usarás con los hombres tiene 30% de probabilidad de caer en Sol (lo que te permitirá conocer el valor de la celda correspondiente) y 70% de probabilidad de caer en Águila (nanai).
Las probabilidades de la moneda que usarás con las mujeres son 60% para Sol (y, por ende, conocer el valor) y 40% para Águila (valor faltante).
Nota bene
Por favor nota que en esta nueva versión del ejemplo, la probabilidad de conocer los valores de las celdas de cada columna depende de los valores de una variable que, primero, sí podemos observar, y, segundo, ya forma parte de nuestra base de datos: el sexo de la persona.
Esta probabilidad será menor para los hombres que para las mujeres (30% vs. 60%).
Si después de echar los 15 volados terminas con uno o más valores faltantes, estos serán aleatorios o Missing At Random (MAR) en inglés.
En este caso los valores faltantes no son completamente aleatorios porque están relacionados con una o más de las variables que sí conocemos e integran nuestra base de datos.
Puesto de otra forma, la probabilidad de que falte un valor es la misma dentro de cada grupo definido por la información que observamos (en este ejemplo, si se trata de una mujer o un hombre), pero difiere entre los grupos (mujeres respecto a hombres).
En la práctica, es mucho más probable que nuestra base de datos contenga valores faltantes aleatorios que completamente aleatorios.
Esto explica la enorme variedad de métodos que existen para lidiar los primeros.
Para entender si los valores faltantes de una variable son aleatorios o no, debemos analizar la relación entre la variable "incompleta" y el resto de las variables en nuestra base de datos.
Al hacerlo, puedes explorar si la frecuencia de los valores faltantes en una variable:
-
Está asociada a valores más grandes/pequeños de las variables numéricas; o,
-
Es significativamente mayor para ciertos valores de las variables categóricas
Si la respuesta es sí, entonces la evidencia sugiere que, efectivamente, los valores faltantes probablemente son aleatorios.
Si la respuesta es no, entonces es probable que se trate de valores faltantes no aleatorios 😮.
Te los presento a continuación.
Este tipo de valores faltantes ocurren por motivos que no conocemos...

O, puesto de otra forma, son valores faltantes que no ocurren de forma completamente aleatoria, y que tampoco están relacionados con una o más de las variables incluidas en la base de datos.
Retomemos el ejemplo de las dos secciones previas una vez más.
A diferencia de los valores faltantes completamente aleatorios y aleatorios, en el mundo de los valores faltantes no aleatorios carecemos de alguna forma para saber qué determina la probabilidad de que podamos conocer o no el valor de una celda.
En este escenario, es probable que nos preguntemos, sin respuesta clara, cosas como:
-
¿La probabilidad de conocer un valor depende de que se "echen" volados?
-
Si es así, ¿se usa uno o varios tipos de monedas?
-
Si son más de una, ¿por qué son más de una y cuáles son las probabilidades de obtener Sol y Águila con cada una de ellas?
-
Si no son monedas, ¿qué otro método se utiliza (p. ej., tirar dados)?
Dada su naturaleza, los valores faltantes no aleatorios son los que representan el mayor reto metodológico, pues es imposible mitigar sus efectos con la información que tenemos a nuestra disposición.
¿Qué podemos hacer entonces?
La próxima semana te platicaré de algunas alternativas para lidiar con estos y los otros dos tipos de valores faltantes.
Hoy termino compartiéndote tres recursos 👇.